1. Introduction
연구 배경 : 최근 거대한 LLMs들이 개발되며, 모델 파라미터 수가 500B를 초과하는 수준에 도달함
→ 훈련에 막대한 연산량과 에너지 비용이 들어감 (훈련 가능한 연산량은 정해져 있는데 ...)
기존 연구의 한계
기존 연구 : 모델 크기가 증가하면, 성능이 향상한다는 power-law 관계를 제시함
→ 연산량이 10배 증가 시, 모델 크기 5.5배 증가, 학습 토큰 수 1.8배 증가해야한다고 주장
→ 즉, 모델 크기를 중심으로 확장해야 성능이 올라간다고 주장함
(like )
본 논문의 아이디어
: 고정된 연산량(FLOPs) 예산이 주어졌을 때, 모델 크기와 훈련 토큰 수의 균형은 어떻게 설정해야 할까?
→ 모델 크기와 토큰 수를 동일 비율로 증가시켜야 성능이 최적화된다고 주장함
본 논문 실험
70M ~ 16B 규모의 400개 이상의 모델을 다양한 토큰 수 5B ~ 400B로 학습하여 실험함
→ 실험 결과, 기존 연구의 결과와 상반된 결론을 도출함을 보임
→ 결과적으로, 모델 크기보다는 충분한 데이터 확보가 성능 향상에 핵심이라는 점을 보임
<Figure 1>
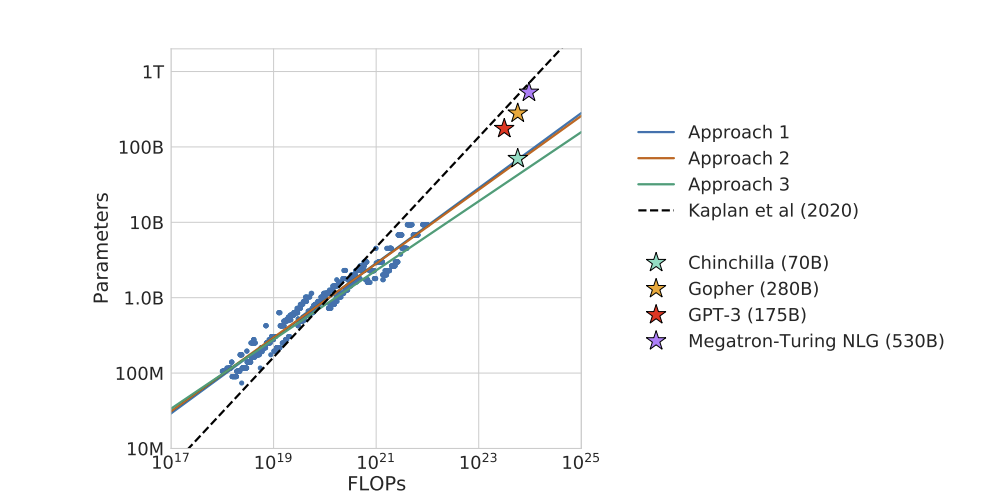
동일한 연산량 자원 예산이라면, 파라미터 수를 너무 크게 잡기 보다는 데이터 토큰 수를 충분히 확보하는 전략이 성능 향상에 더 효과적임을 시각적으로 보여줌
<Table 1>
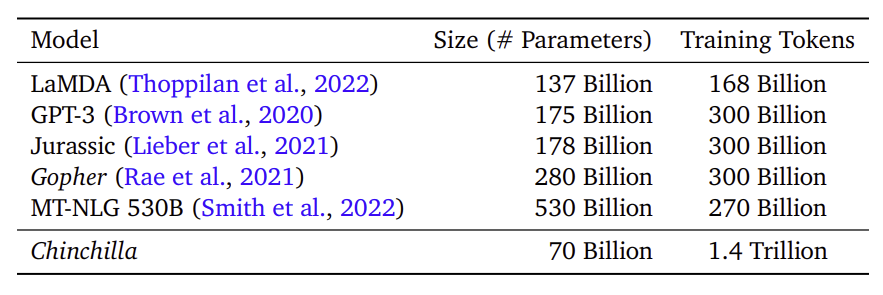
대형 언어모델의 성능을 최대화하려면, 모델 크기와 데이터 규모를 균형 있게 늘리며, 충분한 데이터 확보가 중요함을 보임
3. Estimating the optimal parameter/training tokens allocation
목표 : 고정된 FLOPs 예산 내에서 모델 크기(N)와 훈련 토큰 수(D)를 어떻게 조합해야 최적의 성능을 내는지를 실험적으로 규명하고자 함
3.1 Approach 1: Fix model sizes and vary number of training tokens
실험 주제 : 특정 파라미터 수(N)를 가진 모델을 4가지 다른 학습 토큰 수(D)로 훈련시킴
→ 주어진 FLOPs 수에 대해 달성 가능한 최소 손실값을 직접 추정할 수 있음
실험 설정 : 학습률은 10배 줄이되, 훈련 길이는 16배 범위로 변화시킴
→ 이 FLOPs 예산 안에서 어떤 조합이 최저 손실을 주는가? 를 찾아볼 수 있음
실험 결과 : N_opt∝C^(0.5),D_opt∝C^(0.5)
→ 컴퓨팅 자원이 늘어나면, 모델 크기와 학습 데이터 양을 같은 비율로 증가시키는 것이 가장 좋다는 결과를 보임
(기존 연구에서 말했던 모델크기는 더 크게, 학습 데이터 양은 비교적 조금만 늘리는 것이 좋다고 했던 결과를 기각하는 셈)
3.2 Approach 2: IsoFLOP profiles
실험 주제 : 총 FLOPs를 고정한 후, 다양한 모델 크기(100M ~ 30B 파라미터)를 훈련시켜 최종 손실을 측정함
→ FLOPs 예산이 고정된 상황에서 어떤 모델 크기가 가장 좋은지 직접적으로 판단할 수 있게 됨
실험 설정 : 각 FLOPs 예산에 대해 다양한 모델 크기를 실험하여 손실 곡선을 그리고, 해당 곡선에 포물선을 피팅해 최적 모델 크기와 토큰 수 추정
실험 결과 : N_opt∝C^(0.49),D_opt∝C^(0.51)
→ 마찬가지로, 모델 크기와 학습 토큰 수를 거의 동일한 비율로 늘리는 것이 최적임을 보임
3.3 Approach 3: Fitting a parametric loss function
실험 주제 : Approach 1과 2의 실험 결과를 바탕으로, 파라미터 수와 훈련 토큰 수에 따른 손실을 수학적으로 모델링함
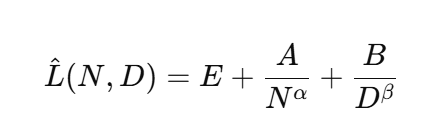
- 첫째 항 : 아무리 좋은 모델이라도 언어 자체가 불확실해서 생기는 예측 불가능성의 한계를 나타냄
- 둘째 항 : 모델 크기가 작을수록 정확도가 떨어지는, 즉 모델 자체가 부족해서 생기는 손실을 나타냄
- 셋째 항 : 학습에 사용한 데이터가 부족할수록 발생하는, 즉 공부량이 부족해서 생기는 손실을 나타냄
파라미터 피팅 방법
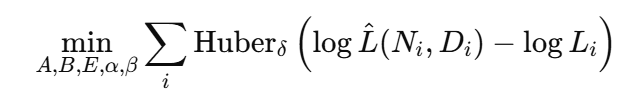
목적 : 5개의 파라미터 A,B,E,α,β를 최적화하기 위함
방법 : 실험에서 얻은 실제 손실값과 위 수식이 예측하는 손실값 사이의 로그 차이를 최소화함 (최적화 알고리즘 L-BFGS 사용)
→ Huber 손실을 사용하는 이유 : MSE보다 이상값에 덜 민감하여 안정적인 파라미터 추정이 가능함
3.4 Optimal model scaling
Approach 1,2,3 의 공통적인 결론 : 계산 예산이 증가할수록 모델 크기와 학습 데이터의 양을 비슷한 비율로 함께 증가시켜야 함
- 1,2 : 최적 모델 크기에 대해 매우 유사한 예측을 보임
- 3 : 계산량이 큰 경우에는 더 작은 모델이 오히려 최적일 수 있음을 보임
현재 LLMs의 문제 : 계산량 대비 너무 큰 모델 크기를 가지고 있음
→ 같은 계산 예산이라면 모델을 줄이는 대신, 토큰 수를 늘렸어야 성능이 더 좋았을 것임
4. Chinchilla
실험 목적 : FLOPs 예산을 고정하고 작은 모델 + 더 많은 학습이 기존의 큰 모델보다 더 효율적인지 검증하기 위함
실험 설정 : Chinchilla와 Gopher 및 다른 LLMs 모델 비교
- 총 연산량 : Gopher와 동일한 수준으로 맞춤
- 파라미터 수 : 70B
- 학습 토큰 수 : 1.4T
4.1 Model and training details
| Gopher | Chinchilla | |
| 데이터셋 | MassiveText | 동일한 데이터셋을 사용하나, 토큰 수 증가를 고려해 샘플링 분포를 일부 변경함 |
| Optimizer | Adam | AdamW |
| Tokenizer | NFKC normalization을 적용한 SentencePiece 사용 | NFKC normalization을 적용하지 않는, 조금 수정된 SentencePiece 사용 |
| 계산 정밀도 | bfloat16 사용 | bfloat16을 사용하지만, optimizer 상태에서는 float32 가중치 저장 |
| 프레임워크 | TPUv3/TPUv4에서 JAX와 Haiku로 학습 | 동일하게 학습 |

4.2 Results
Language modelling
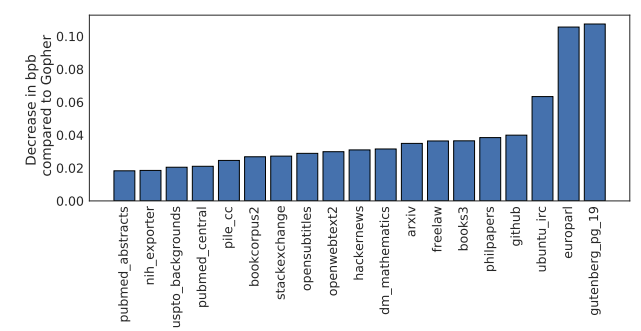
- The Pile 벤치마크 전 서브셋에서 Chinchilla가 Gopher보다 우수한 성능을 보임
- dm_mathematics와 ubuntu_irc에서는 성능 격차 적음 (데이터 누설 가능성)
- Wikitext103에서 더 낮은 perplexity (Chinchilla: 7.16 vs Gopher: 7.75) → 더 정확한 언어 모델임을 입증함
MMLU

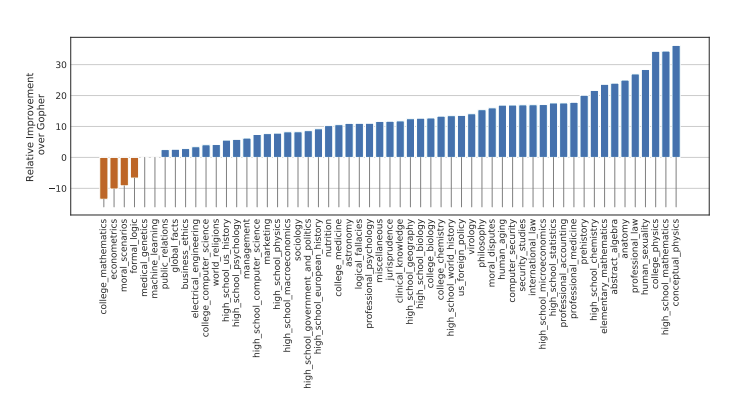
- Chinchilla는 평균 정확도 67.6%로 Gopher보다 7.6%p 높으며, 전문가의 2023년 예측 정확도(63.4%)도 능가함
- Chinchilla는 4개의 개별 과제에서 유일하게 90% 이상의 정확도를 달성함
- 대부분의 과제에서 Chinchilla가 Gopher를 능가했으며, 4개 과제에서는 Gopher가 더 우수했고 2개 과제에서는 동일한 성능을 보임
Reading comprehension
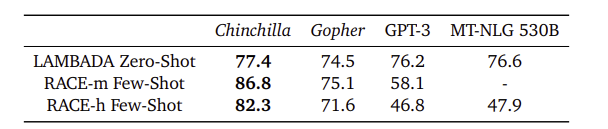
- LAMBADA 데이터셋에서 Chinchilla는 77.4%의 정확도로 Gopher(74.5%)와 MT-NLG 530B(76.6%)보다 더 높은 성능을 보임
- RACE-h 및 RACE-m 벤치마크에서 Chinchilla는 Gopher 대비 정확도 10% 이상 향상되며 압도적인 성능 우위를 나타냄
BIG-bench
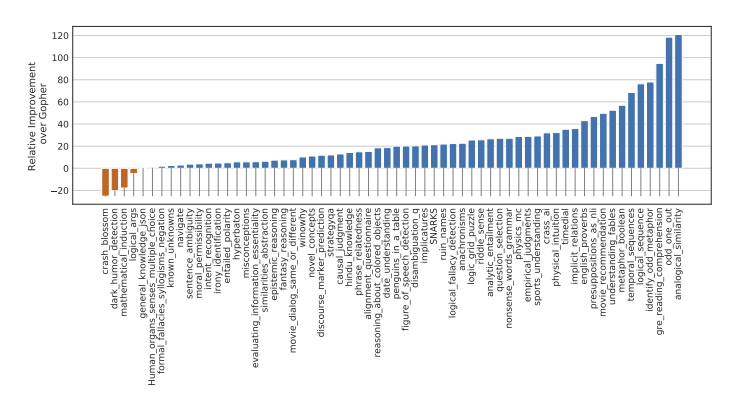
- Chinchilla는 BIG-bench에서 평균 65.1% 정확도를 기록하며, Gopher보다 10.7%p 높은 성능을 보임
- 전체 62개 중 58개 태스크에서 Chinchilla가 Gopher를 능가함
- 단 4개 과제(crash_blossom, dark_humor_detection, mathematical_induction, logical_args)에서 Gopher가 우위를 차지함
Common sense
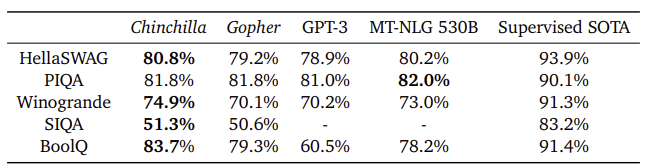
- Chinchilla는 일반 상식 벤치마크에서 Gopher, GPT-3, MT-NLG 530B보다 전반적으로 우수한 성능을 보임
- TruthfulQA에서는 Chinchilla가 Gopher보다 모든 shot 설정(0, 5, 10-shot)에서 큰 정확도 향상을 보였으며, 특히 0-shot에서 14.1%p 높은 성능을 기록함
- 더 나은 사전학습 데이터 모델링만으로도 성능을 크게 향상시킬 수 있음을 시사함
Closed-book question answering
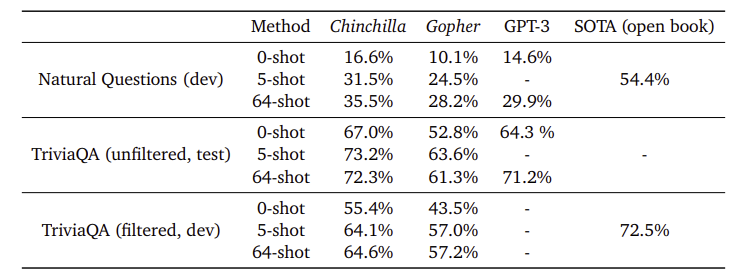
- Chinchilla는 Natural Questions에서 Gopher보다 높은 정확도(5-shot: 31.5%, 64-shot: 35.5%)를 기록함
- TriviaQA에서는 필터링된/비필터링된 셋 모두에서 Gopher를 능가함
- 필터링된 셋에서는 오픈북 SOTA보다 7.9% 낮았고, 비필터링된 셋에서는 GPT-3를 초과하는 성능을 보임
- 전반적으로 닫힌 책 QA에서도 Chinchilla는 강력한 성능을 입증함
Gender bias and toxicity

- Chinchilla는 전반적으로 성별 편향을 덜 반영하지만, 향상 정도는 대명사 유형에 따라 다소 불균형하게 나타남
- 언어 모델의 손실 감소나 성능 향상과 유해성 생성 수준이 직접적인 상관관계가 없음을 시사하며, 더 나은 모델이 반드시 더 유해한 출력을 생성하는 것은 아님을 보여줌
5. Discussion & Conclusion
- 대규모 모델을 여러 번 훈련하기 어렵기 때문에 실험 규모는 제한적이었음
- 토큰 수가 늘어나면서 log(N)에서 오목한 형태(concavity)가 나타나는 등 성능 향상에 한계가 있을 수 있음.
- 본 연구는 오토레그레시브 모델에 초점을 맞췄지만, 다른 모달리티에서도 모델 크기와 데이터 양 간의 trade-off가 있을 것으로 기대됨
- 제안된 방법론은 새로운 환경에서도 쉽게 재현 가능함