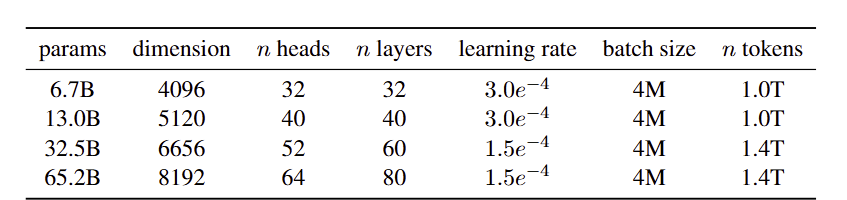
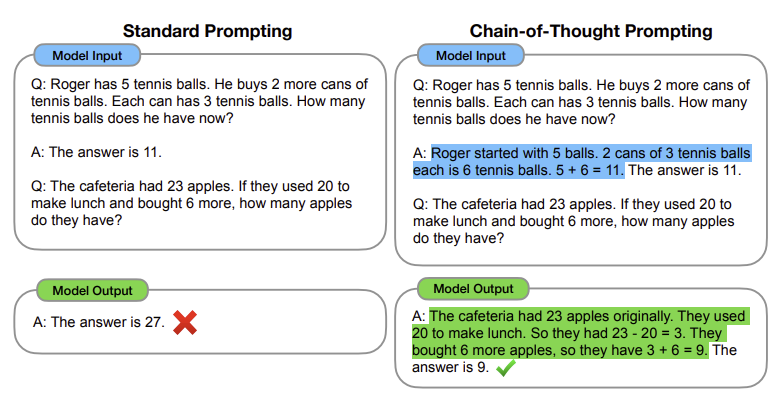
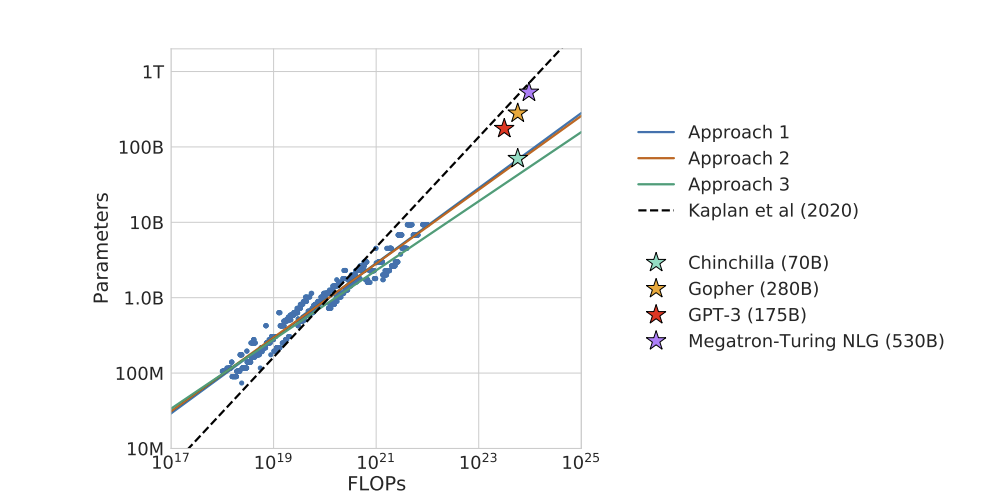
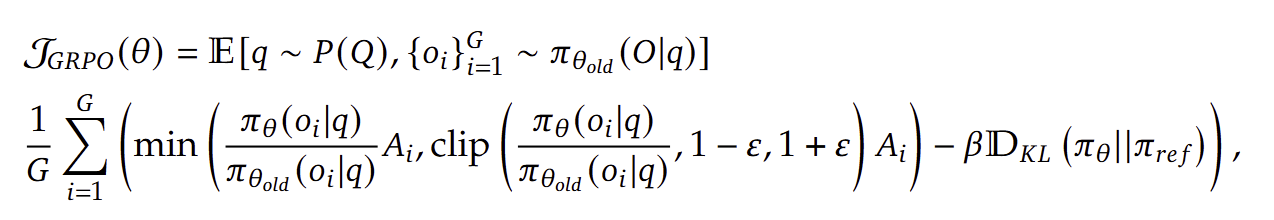Introduction연구 배경수작업으로 설계된 알고리즘 구성 요소들은 더 높은 성능을 보이는 end-to-end 학습 방식으로 대체되어 왔다. 컴퓨터 비전에서는 SIFT와 HOG와 같은 수작업 특징들이 학습된 convolution으로 대체되었고, 자연어 처리에서의 문법 기반 접근 방식은 학습된 transformer로 대체되었다.표형 데이터셋은 텍스트나 이미지와 같은 비가공 데이터 형태와 구별되는 다양한 특성을 가진다.딥러닝 방법들은 전통적으로 표형 데이터에서 어려움을 겪어왔으며, 이는 데이터셋 간의 이질성과 원시 데이터 자체의 이질성 때문이다. 이러한 이유로 트리 기반 모델과 같은 비딥러닝 방법들이 지금까지 가장 강력한 경쟁자로 자리잡아 왔다.기존 연구의 한계전통적인 머신러닝 모델들은 아래와 같은 한계..