1. Introduction
연구 배경 : 언어 모델의 크기를 키우는 것은 성능 향상과 샘플 효율성 증진 등의 다양한 이점들이 있지만, 단순히 모델 크기를 키운다고 해서 어려운 과제에서 높은 성능을 달성하지는 못함
대형 언어 모델의 추론 능력을 끌어낼 수 있는 기존 방법과 한계
1. 자연어 기반 추론 과정 생성 (우리가 푸는 과정 자체를 일일이 자연어로 모델에게 가르치는 것 !)
-> 단순한 입력-출력 쌍보다 훨씬 복잡한 고품질의 추론 데이터를 대량으로 만드는 데 많은 비용이 듦
2. 문맥 기반의 few-shot 학습 (예시 몇 개 던져주고, 알아서 따라해보라고 하는 것 !)
-> 추론 능력이 요구되는 작업에서 잘 작동하지 않으며, 모델 규모를 키워도 성능 향상이 제한적임
본 논문의 아이디어
: 입력, 사고의 흐름(Chain of Thought), 출력⟩ 형태로 구성된 프롬프트를 제시함으로써, 대형 언어 모델이 few-shot prompting만으로 추론이 필요한 과제를 수행할 수 있는지를 탐색하는 방식
본 연구의 의의
: 대형 언어 모델이 대규모 학습 데이터 없이도, 과제에 대한 자연어 기반의 소수의 예시만으로 학습할 수 있음을 보임
2. Chain-of-Thought Prompting
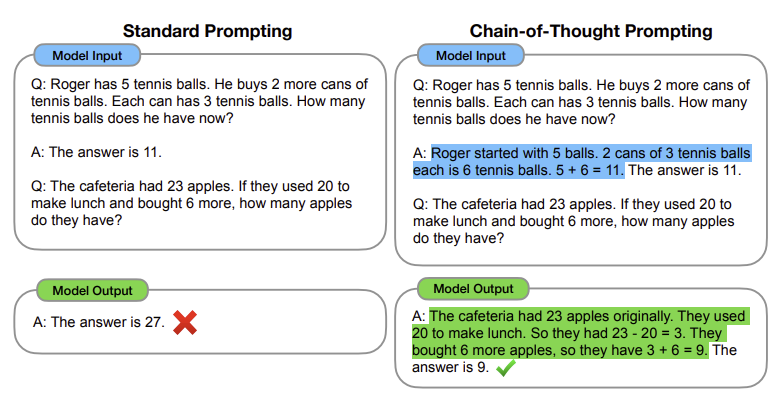
CoT : 사고의 흐름으로, 문제의 최종 답에 이르기까지의 일련의 일관된 중간 추론 과정을 생성하도록 유도하는 방식
CoT의 장점
1. 복잡한 문제를 단계별로 분해할 수 있어, 더 많은 추론이 필요한 문제에 계산 자원을 효과적으로 배분할 수 있음
2. 모델의 추론 과정을 해석할 수 있어, 답이 도출된 이유를 파악하거나 오류 디버깅이 가능함
3. 수학, 상식, 기호 추론 등 다양한 언어 기반 과제에 적용 가능하며, 원칙적으로 인간이 언어로 해결할 수 있는 모든 작업에 활용될 수 있음
4. 예시만 추가하면 쉽게 유도 가능하여, 별도 학습 없이도 대형 언어 모델에서 바로 적용할 수 있음
3. Arithmetic Reasoning
3.1 Experimental Setup
사용한 다섯 가지 수학 문장제 벤치마크
1. GSM8K
2. SVAMP
3. ASDiv
4. AQuA
5. MAWPS
Prompting 비교
- Standard prompting : 문제와 정답으로 이루어진 간단한 입력–출력 예시 몇 개를 제시하여, 모델이 별다른 사고 과정 없이 곧바로 정답을 예측하도록 유도하는 방식
- Chain-of-Thought prompting : 문제와 함께 중간 추론 과정을 포함한 8개의 사고 흐름 예시를 입력으로 주어, 모델이 이를 따라 단계적으로 사고하며 정답에 도달하도록 유도하는 방식
사용한 다섯 개의 대형 언어 모델
1. GPT-3
2. LaMDA
3. PaLM
4. UL2
5. Codex
3.2 Results

첫 번째 결론 : CoT prompting은 작은 모델에서는 성능 향상에 도움이 되지 않으며, 약 100B의 대규모 모델에서만 성능이 향상됨
두 번째 결론 : 복잡한 문제일수록 성능 향상 폭이 큼
세 번째 결론 : GPT-3 175B와 PaLM 540B를 통한 CoT prompting은 기존에 라벨링된 데이터셋으로 파인튜닝한 SOTA 성능을 뛰어넘음
정성적 결과 분석
- 정답의 경우, 사고 흐름이 우연히가 아닌 수학적으로 정확했음
- 오답의 경우, 약 46%는 계산 실수나 단순 누락 등 사소한 오류, 54%는 의미 해석 및 사고 흐름상의 구조적 오류로 인해 나타남
- PaLM 62B → 540B로 확장 시, 사고 단계 누락과 의미 오류가 대부분 해결됨
3.3 Ablation Study
가설 1 : CoT가 수학적 수식을 생성하는 능력 때문에 효과적인 것일 수 있다
→ 실험 : 정답 대신 문제에서 파생된 수식만 출력하도록 prompting을 구성함
→ 결과 : 복잡한 문제에서는 효과 없는 것을 확인함으로써, 단순 수식 생성만으로는 충분하지 않다는 것을 확인함 (다만, 단순 문제에서는 약간의 효과를 보임)
가설 2 : CoT는 단순히 더 많은 연산량을 사용하기 때문에 효과적인 것일 수 있다
→ 실험 : 정답과 관련된 수식의 문자 수만큼 점(…)만 출력하도록 prompting
→ 결과 : 성능은 baseline 수준인 것을 확인함으로써, 연산량 증가만으로는 CoT의 효과를 설명할 수 없음
가설 3 : CoT는 정답 이후 지식을 활성화하는 데만 도움을 주는 것일 수 있다
→ 실험 : 정답 먼저 출력한 뒤, 사고의 흐름을 출력하도록 구성하여 순서를 바꿈
→ 결과 : baseline 수준 성능임으로 확인함으로써, CoT는 단순한 지식 활성화가 아니라 실제 reasoning 구조에 기여함을 확인함
3.4 Robustness of Chain of Thought
가설 : few-shot prompting처럼 CoT prompting도 예시 순서, 문체 작성자에 민감할 것이다
→ 실험 : 작성자 A, B, C는 동일한 문제에 대해 각자 사고의 흐름을 작성했고, A는 추가로 간결한 문체 버전도 만들어 문체와 작성자에 따른 성능 차이를 함께 분석함
→ 결과 : 작성자, 문체, 예시 순서가 달라도 모든 경우에서 CoT prompting은 standard prompting보다 consistently 높은 성능을 보임
4. Commonsense Reasoning
아이디어 : 수학 문제 외에도 상식 추론 과제에서도 CoT prompting이 효과적인지 알아보자 !
사용된 다섯 가지 벤치마크
1. CSQA : 상식 질문
2. StrategyQA : 다단계 전략 추론이 필요한 과제
3. Date Understanding : 주어진 문맥에서 날짜 추론하는 과제
4. Sports Understanding : 스포츠 관련 문장이 타당한지 판단하는 과제
5. SayCan : 자연어 지시를 로봇의 이산적인 행동 시퀀스로 변환하는 과제
Prompting
: 이전과 동일한 방식으로 few-shot 예시를 수동 구성하여 chain of thought 형식으로 제공함
실험 결과

- CoT prompting은 수학 문제뿐 아니라 상식 추론 과제 전반에서도 효과적으로 작동함
- 특히, 대형 모델(PaLM 540B)에서는 SOTA와 사람 수준을 뛰어넘는 성과를 달성함
5. Symbolic Reasoning
아이디어 : 사람에게는 간단하지만 언어 모델에게는 잠재적으로 어려운 상징적 추론을 할 수 있는지 알아보자 !
과제
1. 이름의 각 단어에서 마지막 글자들만 이어붙이는 작업
2. 사람들이 동전을 던졌는지 여부에 따라 동전이 앞면인지 뒷면인지 예측하는 작업
실험
- In-domain : 훈련 예시와 동일한 단계 수의 문제
- Out-of-domain (OOD): 훈련보다 더 많은 단계가 필요한 문제
실험 결과
- In-domain에서는 PaLM 540B + CoT가 두 과제 모두 거의 100% 정답률 달성함
- 작은 모델은 같은 예시를 따라하는 것조차 실패했으며, CoT 효과는 100B 파라미터 이상 모델에서 나타남
- OOD에서는 CoT가 일반 프롬프트보다 성능이 더 좋았지만, 완벽하진 않은 것을 통해, CoT는 훈련 예시보다 더 긴 추론에도 일정 수준 일반화 능력을 보임
6. Discussion
한계
- CoT가 사람의 추론 방식을 모방하기는 하나, 실제 신경망이 이해하는지는 알 수 없음
- CoT도 정확하지 않은 경로로 추론해 잘못된 정답에 도달할 수 있음
→ 더 정교한 생성 메커니즘 개발 필요함
7. Related Work
관련 연구 1 : 중간 추론 단계(intermediate steps)를 사용하는 연구
→ 자연어로 구성된 추론 설명을 통해 문제 해결 단계들을 순차적으로 명시함
↔ 기존 연구가 대부분 태스크별 훈련을 하거나, 데이터셋을 추가 제작했던 것에 반해, 본 연구에서는 사전학습된 언어모델을 추가 학습 없이 활용하며, Chain-of-Thought 프롬프트만으로도 성능 향상을 유도함
관련 연구2 : Prompting
→ 모델 입력부에 효과적인 예시, 설명, 명시적 지시어 등을 추가하여 추론 능력을 개선함
↔ 기존 연구는 대부분 입력 프롬프트를 강화하는 방식이었으나, 본 연구는 출력부에 ‘추론 흐름’을 생성하도록 유도해 결과 출력에 구조적 사고 포함되도록 함
8. Conclusions
- 언어 모델이 수행할 수 있는 추론 과제의 범위를 넓히는 것은 언어 기반 추론 접근 방식에 대한 후속 연구를 촉진할 수 있음