1. Introduction
- 기존 연구 방향
- 대규모 텍스트 말뭉치로 사전학습된 언어 모델을 few-shot으로 새로운 작업에 활용함
- 모델 크기를 키울수록 성능이 향상된다는 관찰 아래, 수천억~수조개 파라미터급 초대형 모델 개발을 진행함 - 기존 연구의 한계
- 주어진 학습 예산 내에서 더 큰 모델 보다 더 많은 토큰으로 학습한 상대적으로 작은 모델이 효율적일 수 있음
- 서비스 환경에서 중요한 추론 속도와 비용을 충분히 반영하지 않아, 대형 모델이 실사용에 적합하지 않을 수 있음
- 대부분의 대형 모델이 비공개 또는 문서화되지 않은 데이터에 의존함 - 본 논문에서의 아이디어
- 7B, 13B, 33B, 65B 파라미터 모델을 포함한 5가지 크기 범위에서, 기존보다 훨씬 많은 토큰으로 학습한 언어 모델인 LLaMA를 제안함
- 완전 공개 소스로만 학습하여, 누구나 재현 가능하고 검증 용이한 오픈소스 모델을 지향함 - 본 논문 아이디어만의 메리트
- 경량화 대비 고성능을 보임
- 단일 GPU 환경에서도 원활히 실행 가능해, 추론 비용 및 지연 시간을 크게 절감함
- 공개 데이터 기반 학습으로, 누구나 손쉽게 모델을 재현 및 확장할 수 있음
2. Approach
2.1 Pre-training Data
- English CommonCrawl [67%]
- C4 [15]
- Github [4.5%]
- Wikipedia [4.5%]
- Gutenbreg and Books3 [4.5%]
- ArXiv [2.5%]
- Stack Exchange [2%]
- Tokenizer : SentencePiece 구현을 활용한 BPE 사용
2.2 Architecture
- Transformer 아키텍처 기반
- Pre-normalization [GPT3]
>> 각 서브레이어 입력을 정규화하여 학습 안정성 강화
- SwiGLU activation function [PaLM]
>> ReLU 대신 Shazeer의 SwiGLU 도입으로 비선형성 및 표현력 향상
- Rotary Embeddings [GPTNeo]
>> 절대 위치 임베딩 제거
- Hyperparameter
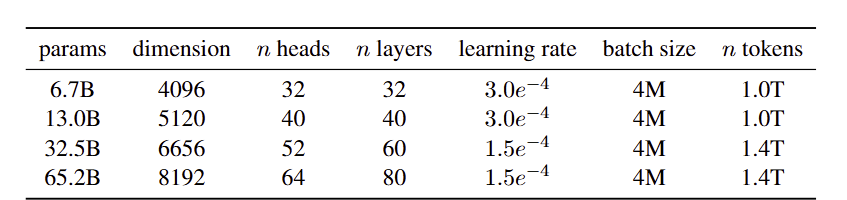
2.3 Optimizer
- 최적화 기법 : AdamW
- 모멘텀 하이퍼파라미터 : beta1 - 0.9 / beta2 - 0.95
- 학습률 스케줄 : 코사인 스케줄
- 정규화 : weight decay = 0.1
- 클리핑 : Max(gradient clipping) = 1.0
- 워밍업 : 2,000 step
2.4 Efficient Implementation
- casual multi-head attention
>> backward를 활용하여 attention 가중치 미저장 및 마스크된 key/query 점수 계산 생략
- check pointing
>> 비용이 큰 activation만 저장하고 나머지는 재계산
- model & sequence parallelism
>> 모델 병렬 및 시퀀스 병렬 사용으로 GPU 메모리 사용량 최소화
3. Main results
- Zero-shot : 태스크에 대한 텍스트 설명과 테스트 예제만 입력해서 모델은 개방형 생성을 통해 답변을 생성하거나, 제안된 답변 후보들을 순위 매기는 방식
- Few-shot : 태스크마다 1개에서 64개 사이의 input–output 쌍과 테스트 예제를 제공해서 모델은 예제와 테스트를 한 번에 입력받아 답변을 생성하거나, 후보들을 순위 매기는 방식
- 비교 모델
- 비공개 대형 모델: GPT-3, Gopher, Chinchilla, PaLM
- 오픈 소스 모델: OPT 계열, GPT-J, GPT-Neo
- Instruction-tuned 모델: OPT-IML, Flan-PaLM
- Multiple choice task
: 주어진 컨텍스트 아래에서 가장 높은 likelihood를 가진 completion 선택하는 방식
(<-> 일반 태스크 : 문자 수로 정규화된 likelihood 사용)
3.1 Common Sense Reasoning
- 벤치마크
- BoolQ
- PIQA
- SIQA
- HellaSwag
- WinoGrande
- ARC easy & challenge
- OpenBookQA
- 설정 : Zero-shot으로 평가
- 결과 비교
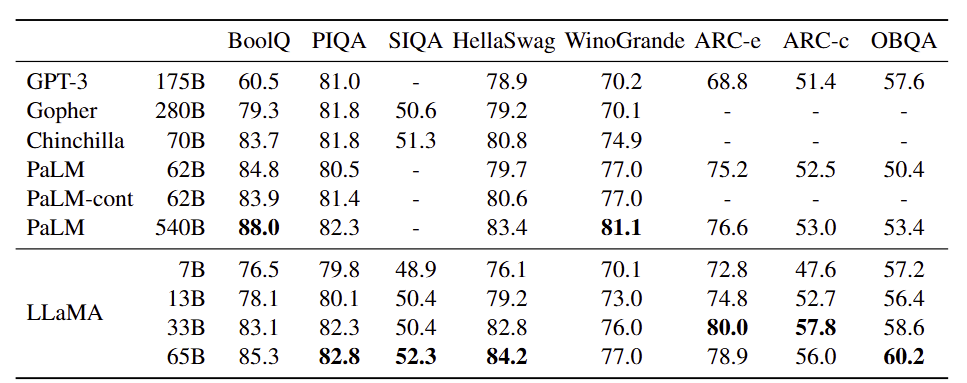
- 경량 모델임에도 대형 모델과 견줄 만한 상식추론 성능 확보함
- 특히 중간 규모(13B, 65B) 모델의 효율성과 경쟁력 입증함
3.2 Closed-book Question Answering
- 벤치마크 : Natural Questions, TriviaQA
- 설정 : Zero-shot 및 Few-shot 모두에서 정확히 일치하는지 성능 평가
- 결과 비교

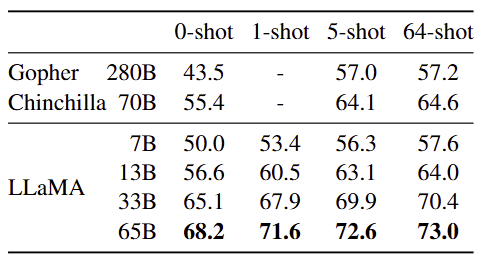
3.3 Reading Comprehension
- 벤치마크 : RACE
- 설정: Language Models are Few-Shot Learners (Brown et al.) 방식
- 결과 비교

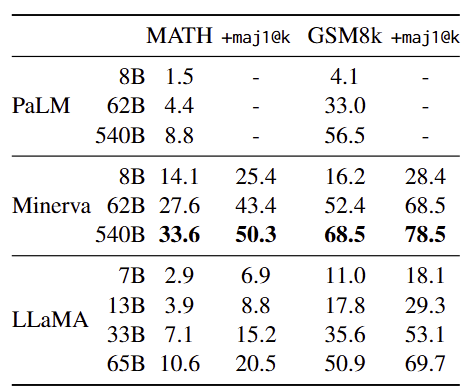
3.4 Mathematical reasoning
- 벤치마크 : MATH, GSM8k
- 비교 대상 : PaLM, Minerva
- 평가 지표 : maj1@k
- 결과 비교
3.5 Code generation
- 벤치마크 : HumanEval, MBPP
- 설정 : 자연어 설명 + I/O 예제, HumanEval은 함수 시그니처 및 docstring 포함
- 평가 지표 : pass@1 (temperature=0.1), pass@100/80 (temperature=0.8), Chen et al.(2021) 방식의 unbiased 추정
- 결과 비교
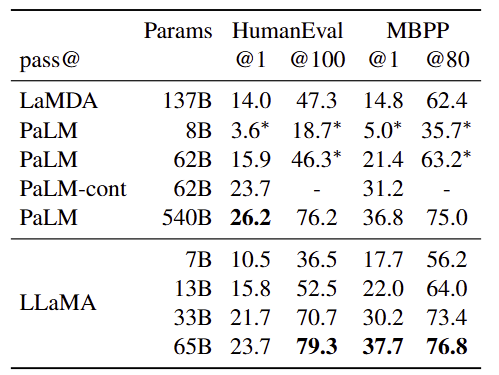
※ 코드 전용 파인튜닝으로 성능 향상 가능하나, 본 연구 범위 밖임
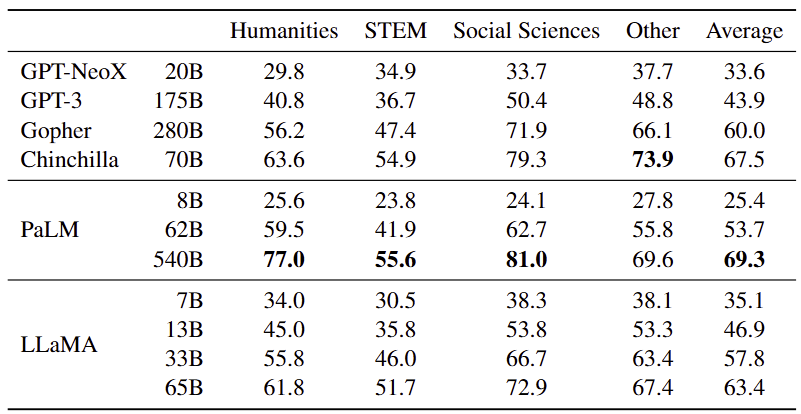
3.6 Massive Multitask Language Understanding
- 벤치마크 : MMLU
- 설정 : 5-shot 평가, 제공된 예제 활용
- 결과 비교
3.7 Evolution of performance during training
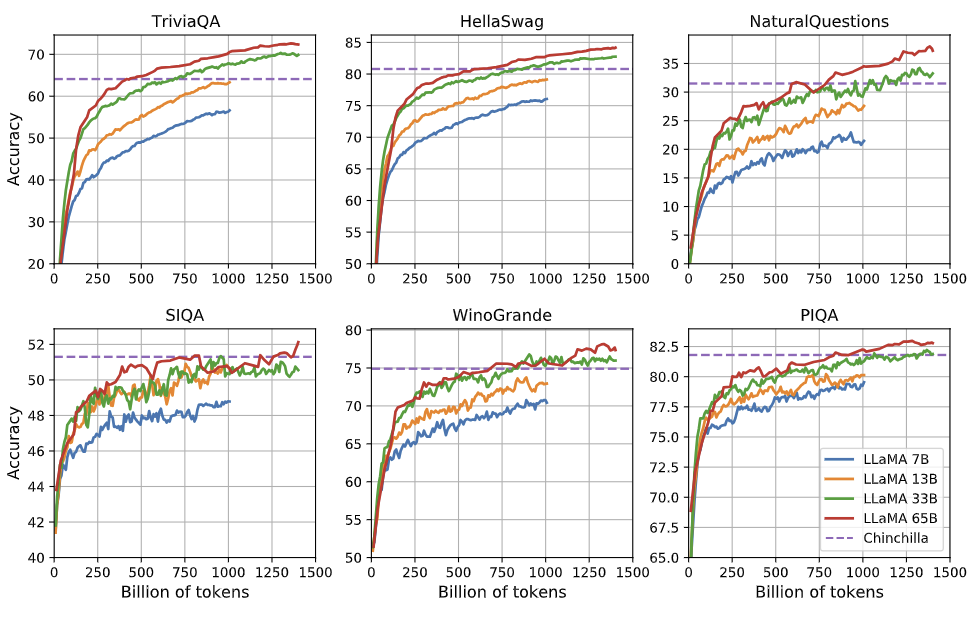
- 거의 모든 그래프에서, 더 많은 토큰으로 학습할수록(→ 퍼플렉서티 감소) 더 높은 정확도를 달성함
- 모델 크기가 클수록 초기부터 더 빠르게, 더 높은 성능을 냄
- 점선을 넘은 구간에서는 LLaMA가 Chinchilla를 앞지르며, 특히 TriviaQA·HellaSwag·NaturalQuestions 등에서 빠르게 역전함
- 아래와 같은 예외적 상황을 보임
- SIQA: 곡선이 들쑥날쑥해 벤치마크 자체의 안정성이 낮을 가능성을 시사
- WinoGrande: 성능 향상 정도가 퍼플렉서티 감소(학습 진행)와 뚜렷하게 상관관계가 없음을 보여 줌
- 중대형 모델(33B, 65B)은 학습 후반부에 유사한 성능 궤적을 보이며, 규모 확장이 가져다주는 이득이 점차 감소함을 암시함
- 의의 : 더 많은 학습 토큰과 더 큰 모델이 대부분의 벤치마크에서 더 나은 성능을 빠르게 확보하지만, 일부 태스크는 별도의 요인(벤치마크 신뢰도, 태스크 특성 등)에 의해 학습 곡선이 예외적일 수 있다 !
4. Instruction Finetuning
- 소량의 instruction 데이터로 파인튜닝이 MMLU 성능을 얼마나 빠르게 끌어올리는지 평가
- 파인튜닝 프로토콜 : Chung et al.의 방식을 그대로 적용하며, 단일 실험만 수행하여 LLaMA-I (65B)를 학습함
- 비교 대상
- 중간 규모 instruction-tuned 모델: OPT-IML, Flan-PaLM 시리즈
- 최첨단 instruction 모델: GPT code-davinci-002
- 결과 비교

5. Bias, Toxicity and Misinformation
- LLaMA-65B가 생성할 수 있는 유해 콘텐츠 및 고정관념 수준을 측정하여, 모델의 윤리적 리스크를 가늠하고자 함.
- 벤치마크 : toxicity·bias·misinformation 평가 도구들을 일부 채택하였으나, 이들 시험만으로는 모델이 내포한 모든 위험 요소를 완전히 진단하기 어렵다는 한계 인식를 인식함
5.1 Real Toxicity Prompts
- 언어 모델이 생성할 수 있는 모욕·혐오·위협 등 유해 언어를 평가함
- Real Toxicity Prompts : 약 10만 개의 프롬프트로 구성된 벤치마크
- 평가 방법 : Real Toxicity Prompts의 각 프롬프트에 대해 모델이 탐욕적 생성한 문장에 PerspectiveAPI로 유해성 점수(0~1)를 산출함
- 결과 비교
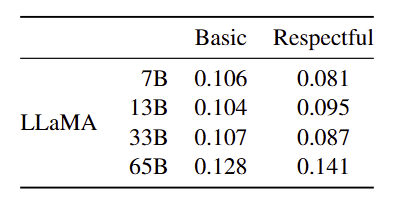
- 시사점 : 정중한 프롬프트에서 모델 크기 증가에 따라 유해성 점수가 상승하는 경향을 관찰함
- 한계점 : 외부 PerspectiveAPI 의존으로 동일 평가 파이프라인을 재현·비교하기 어려움
5.2 CrowS-Pairs
- 고정관념 문장과 반고정관념 문장 중 어떤 문장을 모델이 더 선호하는지 측정하여 사회·문화적 편향을 평가함
- CrowS-Pairs : 성별, 종교, 인종·피부색, 성적 지향, 나이, 국적, 장애, 외모, 사회경제적 지위 등 9개 범주의 편향을 다루는 문장 쌍 데이터셋
- 평가 방법 : CrowS-Pairs의 9개 사회범주별로 고정관념 문장 vs 반고정관념 문장에 대한 모델의 선호도를 제로샷으로 측정하여 편향 점수를 산출함
- 결과 비교

- 시사점 : LLaMA는 평균적으로 GPT-3·OPT-175B보다 약간 더 편향적이며, 특히 종교(OPT 대비 +10%), 그다음 나이·성별 범주에서 편향이 두드러짐
- 한계점 : 문장 쌍 선호만으로 국한된 편향 측정이므로, 실제 다양한 텍스트 생성 맥락에서 나타나는 복합적·암묵적 편향을 완전하게 포착하기 어려움
5.3 WinoGender
- WinoGender (Rudinger et al., 2018) – Winograd 스타일의 공참조 해결 문제로 성별 편향을 측정함
- WinoGender : Winograd schema 기반의 공참조 해결 데이터셋
- 평가 방법 : 제로샷으로 세 가지 대명사 각각에 대한 공참조 해결 정확도를 측정하고, 특히 “gotcha”(직업의 다수 성별과 반대 대명사가 정답인) 사례에서 오류율을 비교함
- 결과 비교
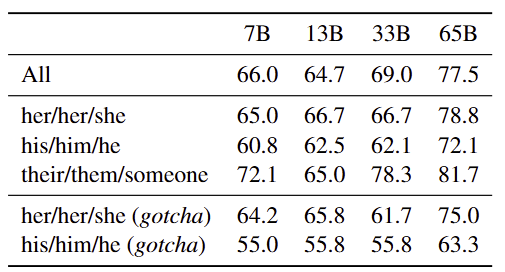
- 시사점 : 모델이 문맥 증거보다 직업의 통계적 성별(예: ‘간호사=여성’)을 우선 사용하여 공참조를 수행, 직업 기반 성별 고정관념을 재현함을 보여 줌
-한계점 : Winograd schema 유형의 공참조 문제에 한정된 평가로, 실제 다양한 대화·생성 상황에서 나타나는 성별 편향을 포괄적으로 진단하기 어려움
5.4 TruthfulQA
- 잘못된 정보나 허위 응답 생성 위험을 측정함
- TruthfulQA : 모델이 “실제 세계에 대한 문자 그대로의 진실”을 얼마나 잘 식별하고 설명하는지를 평가하는 벤치마크
- 평가 방법 : 각 질문에 대해 모델이 생성한 답변의 진실성(true)과 진실하면서도 유용한 정보(truthful ∧ useful) 교집합 정확도를 계산함
- 결과 비교
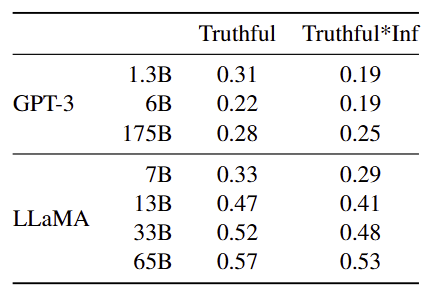
- 시사점 : LLaMA는 기존 모델보다 진실성 면에서 개선되었으나, 여전히 허위 정보 생성 위험이 상당히 남아 있음
- 한계점 : 제한된 수의 적대적 질문 세트로만 평가하므로, 실제 다양한 오정보 시나리오에서의 성능을 완전히 진단하기 어려움
6. Carbon footprint
- 대규모 LLM 훈련에 소요된 총 에너지와 CO₂ 배출량을 정량화하여 환경적 영향을 평가함
- 평가 방법 : GPU 전력 소비량을 PUE=1.1로 조정해 MWh로 환산한 뒤, 미국 평균 탄소 집약도 계수(0.385 kg CO₂eq/kWh)를 곱해 총 CO₂eq 배출량을 산출함
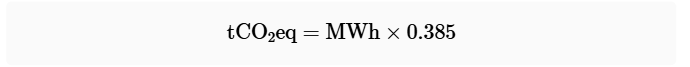
- 결과
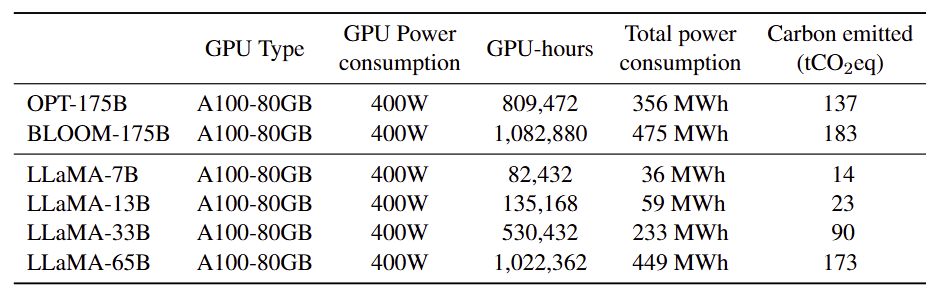
- 의의 : 이미 훈련된 모델 공개로, 후속 연구자는 대규모 재훈련 없이 고성능 LLM 활용이 가능하며, 추가 탄소 배출 절감 기대함
- 한계 : 미국 평균 계수만 사용해 지역별 전력망 특성(청정 에너지 비율 등)을 반영하지 못함 -> 실제 배출량은 다를 수 있음
8. Conclusion
- 한계
- Instruction 파인튜닝 범위 제한: 단일 실험만 수행되어, 다양한 튜닝 데이터·프로토콜에서의 일반화 가능성이 아직 불확실함
- 편향·유해성 평가의 불완전성: 외부 API 의존·제한된 벤치마크 활용으로, 실제 사용 맥락에서의 위험 요소를 모두 포착하지 못함
- 탄소 발자국 추정의 단순화: 미국 평균 전력 계수만 사용해 지역별·기관별 실제 배출량 차이를 반영하지 못함
- 일부 벤치마크 성능 격차: MMLU 등 특정 태스크에서 최첨단 모델과 격차가 존재하며, 대용량 도서·학술 데이터 부족이 요인일 수 있음
- 향후 연구 계획
- Instruction 파인튜닝 심화: Chung et al.(2022) 방식 외에도 다양한 프로토콜과 데이터셋으로 소량의 instruction 학습이 모델 성능에 미치는 영향을 체계적으로 분석함
- 더 큰 규모의 모델 출시: 현재 65B보다 더 많은 파라미터와 방대한 프리트레이닝 코퍼스를 활용한 대형 LLaMA 모델을 개발하여, 스케일링에 따른 성능 향상 여부를 검증함
- 편향·유해성 완화 기법 연구: 현재 평가된 toxicity·bias 지표를 바탕으로, 데이터 필터링·디버깅·후처리 등의 구체적 완화 전략을 설계·테스트함
- 도메인·언어 확장: 법률·의료·과학 등 특정 분야와 비영어권 언어에 특화된 추가 파인튜닝 및 평가를 통해 범용성과 적용성을 높임