1. Introduction
- 기존 LLM의 문제 : 방대한 데이터로 학습해서 뛰어난 능력을 가지지만, 그 데이터에는 원치 않는 행동이나 잘못된 정보도 섞여 있을 수 있음
→ 모든 걸 그대로 쓰게 하면 위험할 수 있기 때문에, 안전하고 유용한 방식으로만 반응하도록 조정해야 함
- 기존 문제 해결 방법 : PPO기반 RLHF
- RLHF : 인간 선호도 데이터셋을 보상 모델에 적합시키고, PPO와 같은 RL을 사용하여 원래 모델에서 과도하게 벗어나지 않으면서 높은 보상을 할당받는 응답을 생성하도록 언어 모델 정책을 최적화시키는 방법
- 문제 : 지도 학습보다 훨씬 복잡하며, 상당한 계산 비용이 발생함
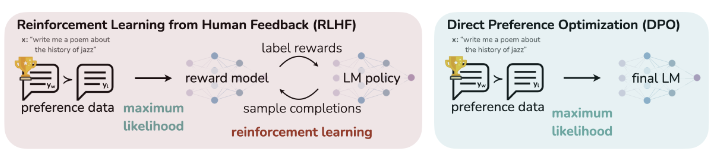
- 본 논문의 아이디어 : DPO
- DPO : 보상 모델링이나 강화 학습을 없애고 인간 선호도에 부합하도록 언어 모델을 직접 최적화하는 방법
- 방법 : 인간 선호쌍에서 도출된 상대적 로그 확률 차이를 기준 모델과의 KL 제약 하에 직접 최적화하여, 명시적 보상 모델이나 강화학습 없이 선호 정렬을 수행하는 방법
→ 학습 과정이 단순하고 안정적이며, RLHF와 비슷한 성능을 유지함
2. Related Work
3. Preliminaries
- Ziegler et al. 이후의 RLHF 파이프라인
- 지도학습 미세조정 (SFT)
- 선호도 샘플링 및 보상모델 학습
- RL 기반 최적화
SFT (Supervised Fine-Tuning) 단계
: 다운스트림 작업에 대한 고품질 데이터에 대한 지도 학습으로 사전 훈련된 LM을 미세 조정하여 모델 πSFT를 얻는 단계
Reward Modeling Phase 단계
- 응답 쌍 생성
: SFT 모델 πSFT(y|x)에 프롬프트 x를 넣어 두 개의 답변 (y1, y2) 를 생성함 - 인간 선호 수집
: 두 답변을 사람에게 보여주고, 더 좋은 답변 yw 과 덜 좋은 답변 yl 을 선택하게 함 ( yw≻yl∣x ) - 보상 함수 가정
: 선호는 우리가 직접 접근할 수 없는 잠재적 보상 모델 r*(x,y)에서 나온다고 가정함 - 선호 모델링
: Bradley-Terry 모델
p∗( y1≻y2∣x ) = exp(r∗(x,y1)) / exp(r∗(x,y1))+exp(r∗(x,y2)) - 보상 모델 학습
: 비교 데이터셋 를 사용해 매개변수화된 보상 모델 rϕ(x,y)(이진 분류 형태 손실) - 구현
: SFT 모델의 마지막 Transformer 레이어 위에 스칼라 출력 레이어를 얹어서 rϕ(x,y) 생성함
RL Fine-Tuning Phase 단계
- 학습된 보상 모델 rϕ(x,y) 이 준 점수를 기준으로, 언어 모델 정책 πθ가 더 높은 보상을 받는 응답을 생성하도록 조정하는 단계
- 최적화 과정에서 KL 제약을 넣는 이유
: 점수만 올리려다 보면 한 가지 답만 반복하는 편향이 생길 수 있어서, 다양성을 유지하고 안정성을 보장하기 위함 - 구현
: PPO라는 강화학습 기법으로 최적화함 - 최적화 수식
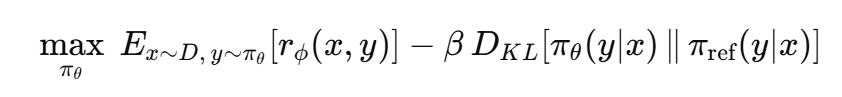
4. Direct Preference Optimization (DPO)
- 목표 : 선호도를 직접 사용하여 정책 최적화를 위한 간단한 접근 방식을 도출하는 것
Deriving the DPO objective
- 기존 RLHF 방식에서의 최적 정책 형태
→ 분할 함수는 가능한 모든 답변을 합쳐서 정규화하는 값이기 때문에 계산이 매우 비쌈

- DPO의 해결 방법
: 최적 정책 식을 로그 변환해서 단순화함
→ Bradley–Terry 모델은 보상 차이만 사용하므로 logZ(x)\log Z(x) 항이 자동으로 사라지기 때문에 분할 함수 계산과 보상 모델 학습을 건너뛸 수 있음

- 선호 확률 표현
: 좋은 답(yw)과 나쁜 답(yl)의 확률 차이를 참조 모델과 비교해서 계산하는 과정

- 최종 DPO 손실
: 보상 모델 없이, 참조 모델 대비 좋은 답 확률은 올리고 나쁜 답 확률은 내리는 방향으로 학습함
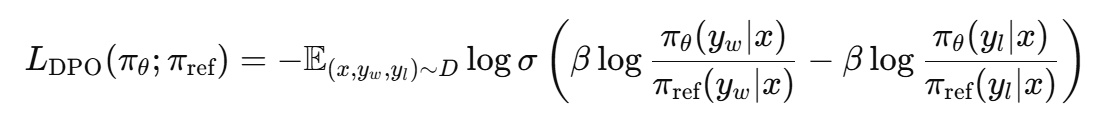
- DPO 모델의 장점
- 보상 모델이 불필요하기 때문에 파이프라인 단순함
- 강화학습 루프가 불필요하기 때문에 PPO 등 복잡한 최적화가 생략됨
- 분할 함수 계산이 없어 속도는 빠르고 비용은 줄어듦
- KL 제약이 암묵적으로 들어 있어 안정성을 유지함
- 기존 RLHF와 비슷한 성능을 훨씬 간단하게 달성함
What does the DPO update do?
- 모델이 어떻게 업데이트될지 (gradient 방향)
- 좋은 답 yw → 확률 ↑
- 나쁜 답 yl → 확률 ↓
- 가중치 : 현재 모델이 나쁜 답을 잘못 높게 평가할수록 더 강하게 업데이트 ( β로 조정 )

- 현재 모델이 참조 모델 대비 해당 답을 얼마나 선호하는지 나타내는 암묵적 보상 값
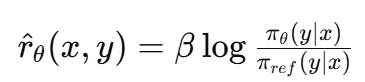
DPO outline
- Data : 참조 모델이 생성한 두 개의 응답을 인간이 비교해 더 나은 것과 덜 나은 것을 라벨링하여 선호도 데이터셋 D를 만듦
- Training : 주어진 참조 모델 π_ref, 데이터셋 , 하이퍼파라미터 β를 사용해 모델 πθ가 DPO 손실 L_DPO를 최소화하도록 학습함
- 직접 데이터 수집 대신 공개 선호도 데이터를 재사용하고, 참조 모델은 가능하면 SFT 모델을 사용하며, 없을 경우 yw 응답 확률을 최대화하는 방식으로 초기화함
5. Theoretical Analysis of DPO
5.1 Your Language Model Is Secretly a Reward Model
- 기존 방식
: 보통 보상 모델 rϕ(x,y)을 먼저 학습한 뒤, 이 보상을 기준으로 정책 πθ를 강화학습(PPO 등)으로 최적화함 - Definition 1 (보상 함수의 동치성)
: 두 보상 함수 r(x,y)r(x, y)와 r′(x,y)r'(x, y)가 다음을 만족하면 동등(equivalent)

- Lemma 1
: Plackett-Luce/Bradley-Terry 모델에서 같은 동치 클래스의 보상 함수는 같은 선호도 분포를 만든다. - Lemma 2
: 같은 동치 클래스의 보상 함수는 같은 최적 정책을 만든다. - 기존 방식의 문제점
- : 보상 모델 학습과 RL 최적화가 별도 단계로 존재하기 때문에, 구현이 복잡하고, 시간이 많이 들 뿐만 아니라, 여러 보상 함수 중 하나를 선택하는 과정이 불필요하게 복잡함
- Theorem 1 (핵심 재매개변수화)
: 약한 가정 하에, 모든 동치 클래스 보상 함수는 다음 형태로 표현이 가능함
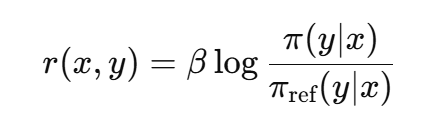
- DPO의 해결
: 보상 모델과 정책 학습을 하나의 MLE(최대 가능도) 최적화로 합침
→ 보상은 참조 정책 대비 현재 정책의 확률 비율로 표현됨
→ 모든 동치 보상 클래스를 표현할 수 있음
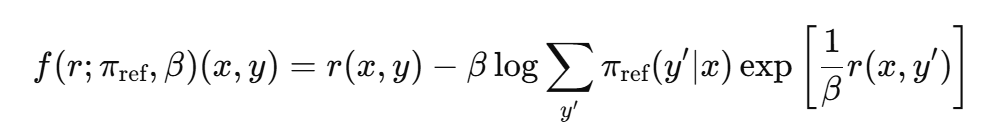
- 장점
- 별도의 보상 모델 학습이 불필요함
- 참조 정책만 있으면 바로 정책 업데이트가 가능함
- 최적 정책을 정확히 복구하면서도 구현이 간단해짐
5.2 Instability of Actor-Critic Algorithms
- 기존 방식
: 보상 함수로 만든 최적 정책과 현재 정책의 KL 거리 최소화를 목표로 함 - 기존 방식의 문제점
: 보상 정규화 항이 없으면 기울기 분산이 커져 학습 불안정해짐 - DPO의 해결
: 재매개변수화로 정규화된 보상을 직접 계산해 기준선을 불필요하게 함 - 장점
- PPO보다 안정적인 학습이 가능함
- 기준선/정규화 과정 제거하여 구현이 간단하고 오차가 감소함
- RL 단계 없이도 RLHF와 같은 효과를 냄
6. Experiments
- DPO가 선호도 학습에서 보상 최대화와 참조 정책과의 KL-divergence 최소화를 PPO 등 기존 알고리즘보다 효율적으로 달성하는지 평가하고자 함
Task
- Controlled Sentiment Generation
- x : IMDb 영화 리뷰 접두사
- 정책 : 긍정적인 감정을 담은 y 생성
- 사전 훈련된 감정 분류기로 평가 ( p(positive|x, yw) > p(positive|x, yl) )
- SFT: IMDb 훈련 데이터를 사용해 GPT-2-large를 수렴까지 미세조정함
- Summarization
- x : Reddit 포럼 게시물
- 정책 : 주요 요점을 요약한 y 생성
- 데이터셋 : Reddit TL;DR + Stiennon et al.의 인간 선호도 데이터
- SFT : TRLX 프레임워크로 인간 작성 요약에 미세조정된 모델을 사용함
- 인간 선호도는 다른 SFT 모델 샘플에서 수집함
- Single-turn Dialogue
- x : 다양한 인간 쿼리
- 정책 : 매력적이고 유용한 응답 생성
- 데이터셋 : Anthropic Helpful and Harmless 대화 데이터
- SFT : 선호된 응답에 대해서만 기성 언어 모델을 미세조정하여 생성함
- 각 대화 말미에 두 개의 LLM 응답과 인간의 선호 레이블 포함함
Evaluation
- 두 가지 평가 접근 방식
- Controlled Sentiment Generation
: 각 알고리즘이 보상 최대화와 레퍼런스 정책과의 KL-divergence 최소화를 얼마나 잘 균형 잡는지 평가
→ 감정 분류기라는 기본 진리 보상 함수를 알고 있기 때문에 프론티어를 계산할 수 있음 - Summarization & Single-turn Dialogue
→ 실제 환경에서는 기본 진리 보상 함수가 없으므로, GPT-4를 인간 평가의 프록시로 사용함
(요약 baseline : 테스트 세트 레퍼런스 요약 / 대화 baseline : 선호 응답)
- Controlled Sentiment Generation
- GPT-4 사용 근거
: GPT-4에 대한 인간의 동의 수준이 인간 주석가 간의 동의 수준과 유사하거나 더 높음
Methods
- Prompting 기반 접근
- 요약 : GPT-J를 사용한 zero-shot prompting
- 대화 : Pythia-2.8B를 사용한 2-shot prompting
- Supervised Fine-Tuning 기반 접근
- SFT : 제어된 감성/요약 작접에서는 SFT 모델 사용
- Preferred-FT : 대화 작업에서는 일반 LM에 대해, 선호된 completion yw에 지도학습으로 파인튜닝
- Pseudo-supervised 방법 (Unlikelihood)
- yw의 확률은 최대화, yl의 확률은 최소화하는 방식 (unlikelihood 항에 선택적 계수 α 사용)
- RL 기반 접근
- PPO : 선호도 데이터에서 학습된 보상 함수 사용
- PPO-GT (Oracle) : 제어된 감성에서 사용 가능한 ground truth 보상 함수 사용
(ver1 : 기본 버전 / ver2 : 보상 정규화 및 하이퍼파라미터 추가 조정으로 성능 개선)
- Best of N
- SFT 모델에서 N개의 응답 샘플을 뽑아 보상 모델 점수가 가장 높은 응답 선택
→ 장점 : PPO 최적화와 보상 모델 품질을 분리할 수 있음
→ 단점 : 테스트 시 모든 쿼리에 대해 N개를 생성하기 때문에 계산량이 매우 큼
- SFT 모델에서 N개의 응답 샘플을 뽑아 보상 모델 점수가 가장 높은 응답 선택
6.1 How well can DPO optimize the RLHF objective?
- 실험 목표
: RLHF에서는 보상 극대화와 참조 정책과의 차이(KL-divergence) 최소화를 동시에 달성해야 하는데, DPO가 이 두 가지를 얼마나 효율적으로 균형 잡을 수 있는지를 검증하고자 함 - 아이디어
: 보상과 KL 사이의 관계를 보상-KL 프론티어로 비교하면서 , 이 프론티어가 낮은 KL에서 높은 보상을 달성할 수 있는지 실험 - 실험 방식
- task : Controlled Sentiment Generation
- 비교 대상 : DPO, PPO, PPO-GT(정답 보상 사용), Unlikelihood, Preferred-FT 등
- 총 22번 학습 실행, 각 실행에서 매 100스텝마다 테스트 프롬프트로 평가함
→ 평균 보상과 평균 KL 계산함
- 실험 결과
- DPO가 모든 구간에서 낮은 KL을 유지하면서 가장 높은 보상 달성함
- PPO와 같은 목표를 쓰지만 효율이 훨씬 높으며, 심지어 PPO가 ground truth 보상(PPO-GT)을 사용할 때보다도 더 좋은 프론티어를 형성함을 보임
6.2 Can DPO scale to real preference datasets?
- 실험 목표
: DPO가 실제 인간 선호 데이터가 포함된 다양한 작업에서도 높은 성능을 유지할 수 있는지 검증하고자 함 - 아이디어
: 자동 평가 지표(ROUGE 등)는 인간 선호도와 상관이 낮으므로, GPT-4 기반 승률 평가를 사용해 비교함 - 실험 방식
- task1 : Summarization
- Model : GPT-J SFT
- 비교 대상 : DPO, PPO, Preferred-FT, Best of N
- 동일한 SFT 모델을 각 방법으로 fine-tuning 후, 다양한 샘플링 온도(0.0~1.0)에서 생성
→ 참조 요약 대비 평균 승률 계산
- task2 : Single-turn Dialogue
- Model : Pythia-2.8B (SFT 없음)
- 비교 대상 : DPO, Best of 128, Pythia-2.8B 2-shot prompting, PPO 기반 RLHF 모델
- Preferred-FT로 사전 fine-tuning 후 DPO 학습
→ GPT-4 평가로 생성 응답의 선호 승률 계산
- task1 : Summarization
- 실험 결과
- Summarization
- DPO(온도 0.0) 승률 약 61%로, PPO(57%) 및 Best of N보다 우위임을 보임
- 샘플링 온도 변화에도 PPO보다 성능 저하가 적음 (더 안정적임)
- Preferred-FT는 SFT 대비 큰 향상 없음
- Single-turn Dialogue
- DPO가 Best of 128 수준의 성능을 효율적으로 달성함 (계산량이 훨씬 적음)
- PPO 기반 RLHF 모델은 기본 모델보다 개선된 프롬프트/온도를 찾지 못함
- DPO가 선호 응답 품질에서 안정적 우위 확보함
- 학습 속도도 빠르게 수렴함
- Summarization
6.3 Generalization to a new input distribution
- 실험 목표
: 학습 데이터와 다른 분포(CNN/DailyMail 뉴스 기사)에서 DPO의 일반화 성능 평가를 하고자 함 - 평가 방식
: GPT-4로 ground truth 요약 대비 승률 계산, 샘플링 온도 0 / 0.25에서 측정 - 결과
- DPO: 0.36(온도 0), 0.31(온도 0.25)
- PPO: 0.26(온도 0), 0.23(온도 0.25)
- DPO가 PPO보다 새로운 분포에서도 높은 승률을 기록하며 일반화 성능 우수함을 보임
6.4 Validating GPT-4 judgments with human judgments
- 실험 목표
: GPT-4의 자동 평가 결과가 인간 판단과 얼마나 일치하는지 검증하기 위해 TL;DR 요약 실험에서 인간 평가를 수행하고자 함 - 실험 방식
- 두 가지 GPT-4 프롬프트를 사용함
- GPT-4 (S): 중요한 정보를 더 잘 요약한 쪽 선택
- GPT-4 (C): 더 간결한 요약 선택
- 비교 대상 : DPO(온도 0.25, 최고 성능), SFT(온도 0.25, 중간 성능), PPO-1(온도 1.0, 최저 성능)
- 인간 응답자 수: DPO 272명, SFT 122명, PPO-1 199명
- 두 가지 GPT-4 프롬프트를 사용함
- 실험 결과
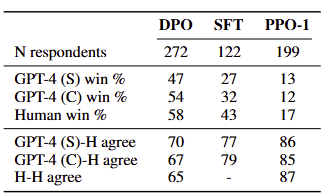
- GPT-4는 인간 평가의 합리적인 대체 지표로 활용 가능하며, 특히 GPT-4 (C) 프롬프트가 인간 판단을 더 잘 반영함을 보임
7. Discussion
Limitation
- Out-of-distribution generalization
: 초기 실험에선 PPO와 비슷한 성능을 보였지만, 더 광범위한 검증이 필요함 - Self-labeling
: DPO가 레이블 없는 프롬프트를 효과적으로 활용 가능한지 검증되지 않음 - Over-optimization
: 성능 저하 사례가 보상 과잉 최적화 때문인지 불분명함
Future Work
- 고품질 자동 평가 프롬프트 설계 연구
- 언어 모델 외에도 다른 생성 모델 및 모달리티에 DPO 적용 가능성 연구