1. Introduction
연구 배경
- 추론 능력의 중요성 : 추론 능력은 인간 지능의 핵심 요소이며, 수학 문제 해결, 논리적 추론, 프로그래밍과 같은 복잡한 인지 작업 수행이 필수적이다.
- 추론 능력 향상을 위한 방법론 등장 :
- Chain-of-Thought(CoT) 프롬프팅을 사용하면, 모델이 중간 추론 과정을 생성하면서 복잡한 문제 해결 성능이 향상된다.
- post-training 단계에서 multi-stop reasoning trajectory를 학습하면, 추가적인 성능 향상이 관찰된다.
기존 연구의 한계
- 인간 주석에 의존하기 때문에, 확장성이 제한되고, 동시에 인지적 편향이 도입될 수 있다.
- 모델이 인간의 사고 과정을 그대로 모방하도록 제한되기 때문에, 성능이 인간이 제공한 예시의 수준에 의해 제한된다.
- 인간 추론 패턴을 모방하도록 제한되어, 비인간적이고 더 효율적인 추론 전략을 발견하기 어렵다.
기존 연구의 수정 방향 및 한계
- 수정 방향 아이디어 : 인간 추론을 모방하는 것이 아니라 정답 기반 reward만 제공하여 자율적인 추론 학습을 유도하자 !!
- DeepSeek-R1-Zero
- SFT 없이 RL만으로 추론 능력을 학습한다.
- 최종 답의 정확도만 reward로 사용한다.
- 추론 과정에는 제약을 두지 않는다.
- 한계
- 가독성이 낮다.
- 한 응답의 CoT 내부에서 영어와 중국어가 혼합되는 현상이 발생하기도 한다.
- reasoning task에만 특화되어 있어.writing 및 general QA 성능이 제한된다.
DeepSeek-R1 제안
- DeepSeek-R1의 multi-stage training pipeline :
- rejection sampling : RL 과정에서 생성된 다양한 reasoning trajectory 중 품질이 높은 reasoning 데이터만 선택해, 고품질 reasoning 데이터셋을 구축한다.
- reinforcement learning (RL) : Group Relative Policy Optimization 기반 RL을 적용한다.
- supervised fine-tuning (SFT) : rejection sampling으로 선별된 데이터를 활용하여 지도학습을 수행해, 모델의 출력 품질을 향상시키고 가독성, 언어 일광선, 일반적인 QA 및 writing 능력을 개선한다.
2. DeepSeek-R1-Zero
- DeepSeek-R1-Zero의 학습 방식 : SFT를 사용하지 않고, 오직 강화학습에만 의존하여 학습된다.
2.1 Group Relative Policy Optimization
GRPO
- DeepSeek-R1-Zero와 DeepSeek-R1을 학습하기 위해 사용하는 강화학습 알고리즘으로, PPO의 학습 과정을 단순화하고 자원 사용량을 줄이기 위해 제안되었다.
- 학습 방식 :
- 이전 정책으로부터 여러 개의 출력을 샘플링한다
- 이후 정책 모델을 다음 목적함수를 최대화하도록 최적화한다.
(목적함수의 의미 : 좋은 답변의 확률은 높이고, 나쁜 답변의 확률은 낮추면서, 모델이 갑자기 크게 변하지는 않도록 한다.)
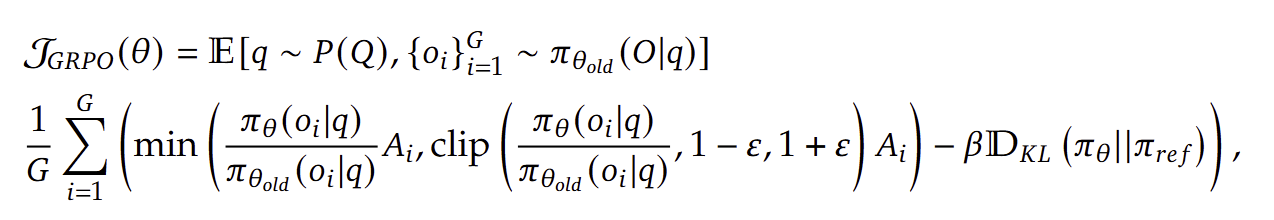
※ KL divergence
- policy가 reference model에서 너무 멀어지는 것을 방지하는 수식이다.

※ Advantage :
- 답변들 사이의 상대적 품질을 학습시키는 수식이다.

학습 설정
- learning rate : 3e-6
- KL coefficient : 0.001
- sampling temperature : 1
- 토큰 길이 제한 : 32,768 tokens → 65,536 tokens
- 각 질문마다 16개의 출력을 샘플링한다.
학습 과정
- 총 10,400 training steps (약 1.6 training epochs)
- 각 step마다 32개의 질문, batch size = 512
- 400 step마다 reference model을 최신 policy로 업데이트한다.
- 훈련을 가속하기 위해 각 rollout에서 8,192 outputs 생성하고, 이를 16 mini-batch로 나누어 학습한다.
Prompt Template
- [추론 과정] - [최종 답] 을 생성하도록 요구한다.
<think> reasoning process </think>
<answer> final answer </answer>
2.2 Reward Design
rule-based reward
- Accuracy reward : 모델의 최종 답이 정답인지 여부를 평가한다.
- Format reward : 모델이 정래진 출력 형식을 따르도록 유도한다.
최종 Reward
Reward_rule = Reward_acc + Reward_format
Neural reward model을 사용하지 않는 이유
- reward hacking
- 추가 계산 비용
- 훈련 파이프라인 복잡도 증가
2.3. Incentivize Reasoning Capability in LLMs
학습 방식
- DeepSeek-R1-Zero는 DeepSeek-V3 base 모델 위에서 강화학습(RL)을 적용하여 학습된다.
- 모델의 추론 능력을 자연스럽게 관찰하기 위해 제약을 최소화한다. (reasoning 구조는 요구하되, 특정 reasoning 전략은 강제하지 않고, 내용에 대한 추가적인 규칙도 두지 않는다.)
성능 결과
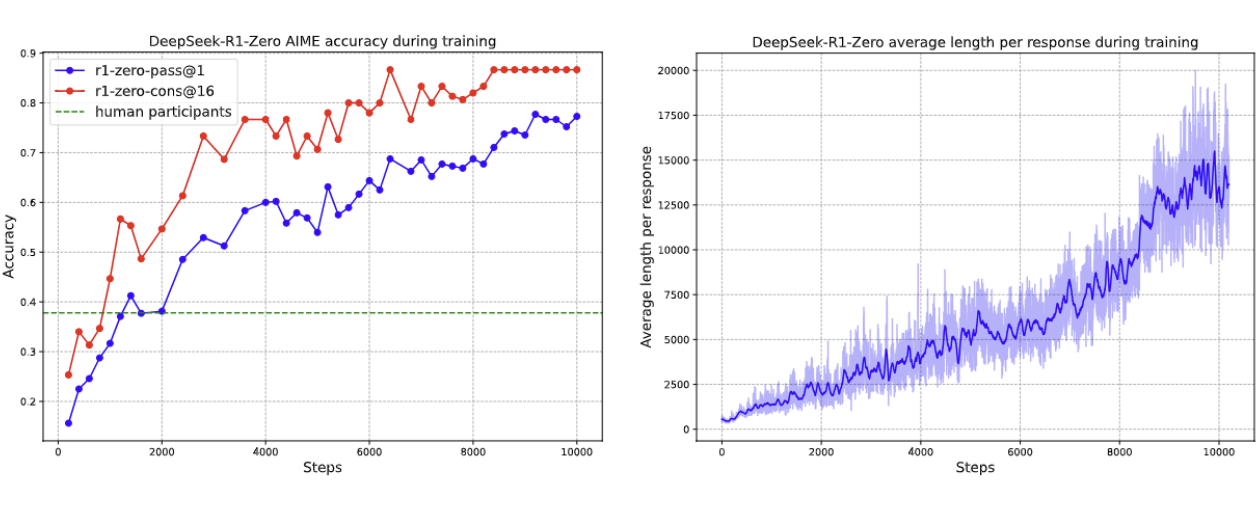
- RL 학습을 통해 AIME 2024 benchmark 성능이 15.6%에서 77.9%까지 크게 향상되었다.
- self-consistency decoding을 적용하면 성능은 86.7%까지 향상되며, 이는 AIME 인산 평균 성능을 크게 초과하는 결과이다.
학습 진행에 따른 특징적인 변화
- Thinking Time의 증가 : 훈련이 진행될수록 모델의 응답 길이가 점차 증가되며, 이는 모델이 더 많은 추론 과정을 탐색하고 있음을 의미한다.
- 고급 reasoning 전략 : 학습 과정에서 아래와 같은 고급 reasoning 전략을 자연스럽게 학습한다.
- Reflective reasoning : 이전 reasoning을 다시 검토한다.
- Alternative solution exploration : 여러 해결 방법을 탐색한다.
- Aha Moment : 모델이 자신의 reasoning을 다시 평가하고 수정하는 행동을 보이며, 연구에서는 이를 RL 기반 self-evolution 과정의 증거로 본다.

DeepSeek-R1-Zero의 의의
- RL은 명시적인 reasoning instruction 없이도, 모델이 자율적으로 문제 해결 전략을 발전시킬 수 있도록 한다.
3. DeepSeek-R1
DeepSeek-R1-Zero의 한계
- 가독성이 낮다.
- 언어 혼합 문제가 발생한다.
DeepSeek-R1의 파이프라인
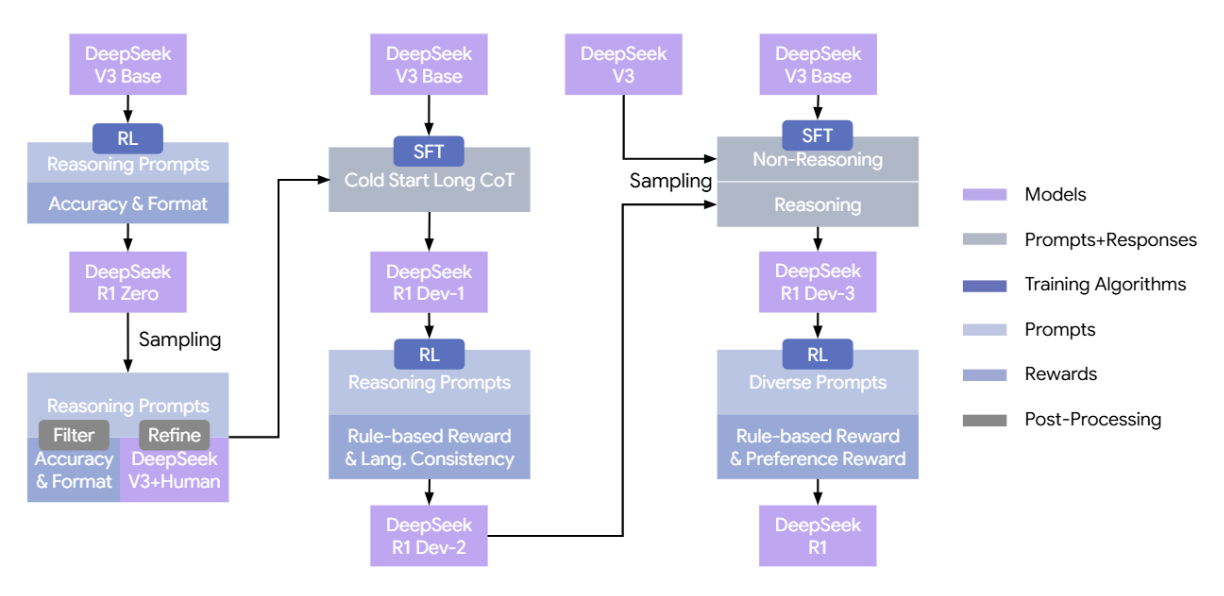
- Cold-Start Data 수집 :
- conversational thinking process이면서 human-like reasoning을 가진 데이터를 수집한다.
- ▶ 모델이 초기 reasoning 스타일을 안정적으로 시작하도록 한다.
- 첫 번째 RL :
- 알고리즘 : GRPO
- 추가 reward : Language consistency reward
→ target language 비율이 높을수록 reward 증가하는 구조이다. - ▶ RL을 통해 reasoning 능력과 언어 일관성을 개선하고, language mixing 문제를 해결한다.
- Rejection Sampling + SFT :
- rejection sampling을 거친 후, SFT를 수행한다. (reasoning data와 non-reasoning 데이터 모두 사용)
- ▶ reasoning 성능을 유지하면서, writing 능력을 향상시킨다.
- 두 번째 RL :
- human preference alignment를 수행한다.
- ▶ helpfulness, harmlessness, reasoning refinement의 안정적인 성능을 기대한다.
3.1 Model-based Rewards
Heplful Reward Model
- 답변이 얼마나 유용한가 (66,000 pair)
- 각 response에 대해 score를 계산한다.
- 모델이 더 좋은 응답에 더 높은 score를 주도록 학습한다.
- 최종적으로 어느 응답이 더 좋은지 판단한다.
Safety Reward Model
- 답변이 안전한가 (106,000 prompt)
- 모델이 응답 하나에 대해 안전 점수를 계산한다.
- 각 응답에 대해 label을 붙여 binary classification를 진행한다.
- 최종적으로 응답이 얼마나 안전한지 score로 평가한다.
3.2. Training Details
3.2.1. Training Details of the First RL Stage
목적
- 추론 능력 강화
- 언어 일관성 개선
- 모델의 reasoning 품질 향상
학습 설정
- 알고리즘 : GRPO
- 주요 하이퍼파라미터
- learning rate: 3e-6
- KL coefficient: 0.001
- GRPO clip ratio εε: 10
- sampling temperature: 1
- 각 step마다 32개의 질문, batch size = 512
- 400 step마다 reference model을 최신 policy로 업데이트한다.
- 훈련을 가속하기 위해 각 rollout에서 8,192 outputs 생성하고, 이를 16 mini-batch로 나누어 학습한다.
Language Consistency Reward
- language mixing 문제를 줄이기 위해 language consistency reward를 추가한다.
(reasoning data와 non-reasoning 데이터 모두 사용)

3.2.2. Training Details of the Second RL Stage
목적
- 추론 능력 유지
- helpfulness 향상
- safety 향상
- human preference alignment
학습 데이터
- Reasoning Data
- reward : rule-based reward
- 대상 : math, coding, logical reasoning
- General Data
- reeard : reward model 기반 reward
최종 reward
Reward = Reward_reasoning + Reward_general + Reward_language
학습 설정
- temperature = 0.7 제외하고는 first RL stage와 동일하다.
- 총 1700 training steps, 마지막 400 stps에는 instruction data, preference reward 적용한다.
→ reward model 기반 학습을 오해 하면, reward hacking이 발생하기 때문에 preference reward는 마지막 단계에서만 적용한다.
4. Experiment
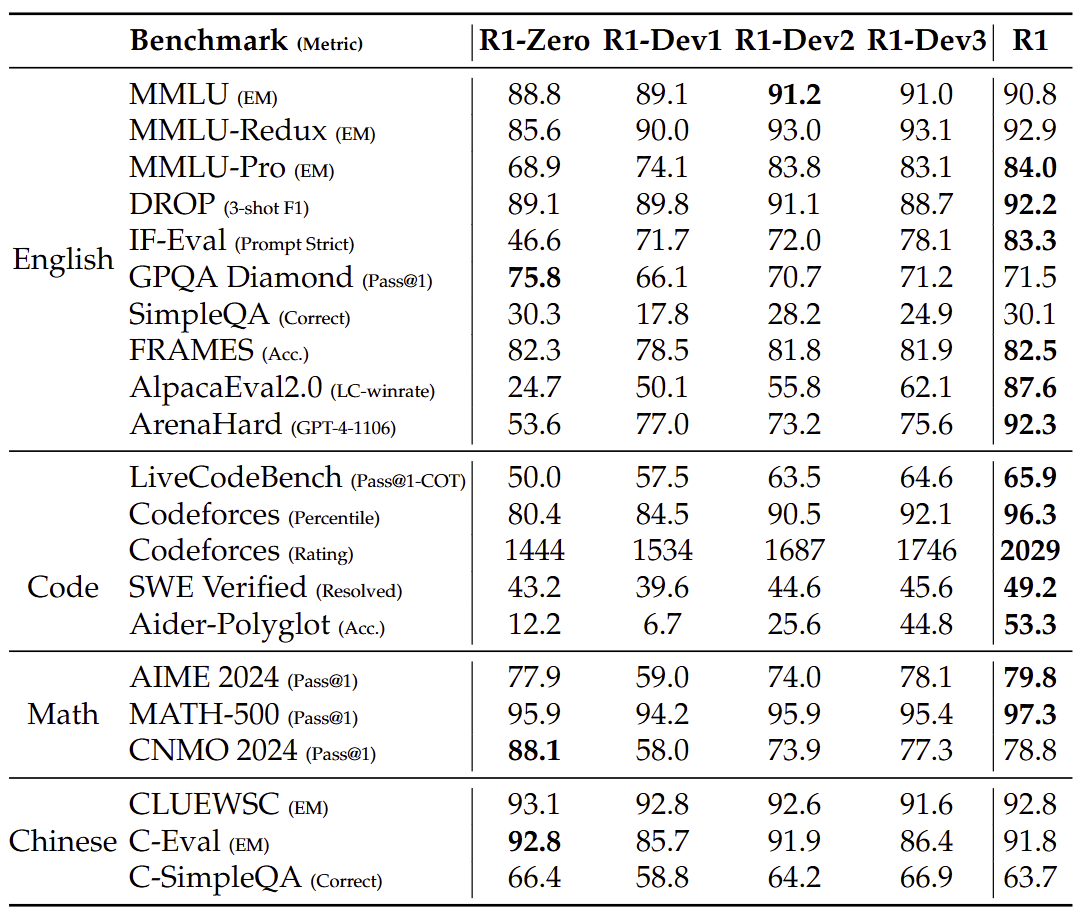
실험 결과
- RL은 reasoning 능력을 크게 향상시킨다.
- RL만으로는 general task가 부족하다.
- 일반 데이터 SFT가 필요하다.
5. Ethics and Safety Statement
6. Conclusion, Limitation, and Future Work
의의
- 인간 CoT 데이터 없이도 reasoning을 학습할 수 있다.
- reasoning 능력은 RL로 크게 향상된다.
- reasoning을 위한 핵심은 human data가 아니다.
한계
- 모델의 한계
- Structured Output 및 Tool 사용 부족
- Token Efficiency 문제
- Language Mixing
- Prompt 민감성
- Software Engineering Task 성능
- RL 방법론 자체의 한계
- Reward Hacking
향후 연구 방향
- 더 강력한 Reward Model
- Tool-augmented Reasoning
- Verifiable Task 중심 RL 확장